
Projects
Understanding Weight Normalized Deep Neural Networks
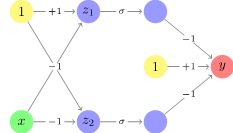
We presents a general framework for norm-based capacity control for Lp,q weight normalized deep neural networks (DNNs). We consider the practical network architecture with a bias neuron per hidden layer. The example below demonstrates the failure of current norm-based constraints on fully connected neural networks with the bias neuron in each hidden layer, as the output could go to infinity even if the product of the norm of each layer is bounded. We then establish the upper bound on the Rademacher complexities of the Lp,q weight normalized DNNs. For the regression problem, we provide both the generalization bound and the approximation bound. We argue that the approximation error can be controlled by the L1 norm of the output layer for any large enough L1, 8 weight normalized neural network. As L1, infinity weight normalization indicates local sparsity, we further introduce the sparse DNNs. Finally, we develop an efficient algorithm for sparse DNNs, and evaluate its effectiveness through synthetic as well as real-world experiments.
Nonlinear Feature Selection via Deep Neural Networks
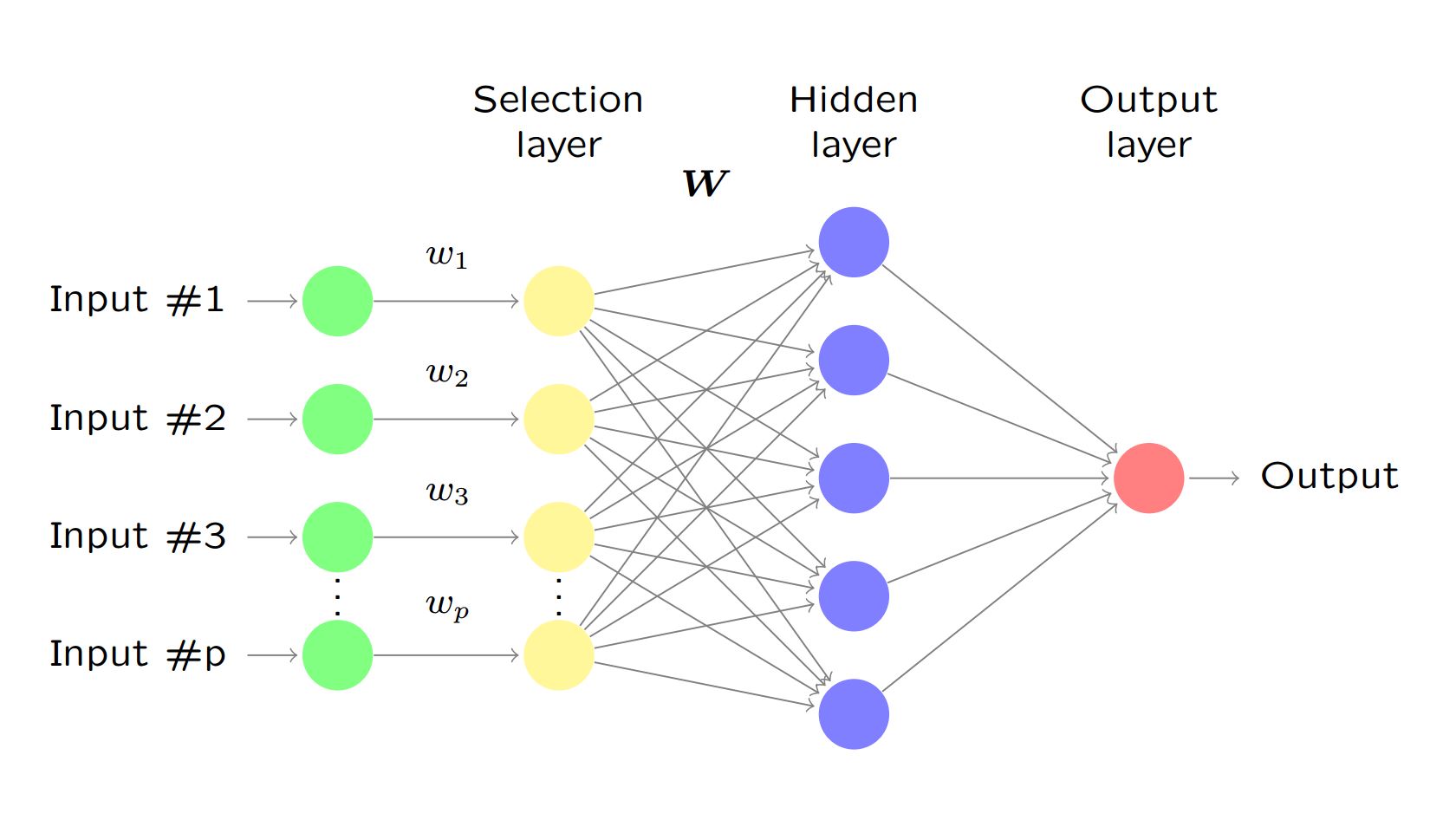
This paper presents a general framework for high-dimensional nonlinear feature selection using deep neural networks under the setting of supervised learning. The network architecture includes both a selection layer and approximation layers. The problem can be cast as a sparsity-constrained optimization with a sparse parameter in the selection layer and other parameters in the approximation layers. We propose a greedy algorithm, Deep Feature Selection (DFS), to estimate both the sparse parameter and the other parameters. We establish that, when the objective function has a Generalized Stable Restricted Hessian, our algorithm has a theoretical convergence guarantee. This result generalizes known results for high-dimensional linear feature selection. Further, DFS demonstrates superior performance over other competing algorithms through numerical simulations and real data.
High Dimensional Inference via Adaptive Bayes and Deep Learning
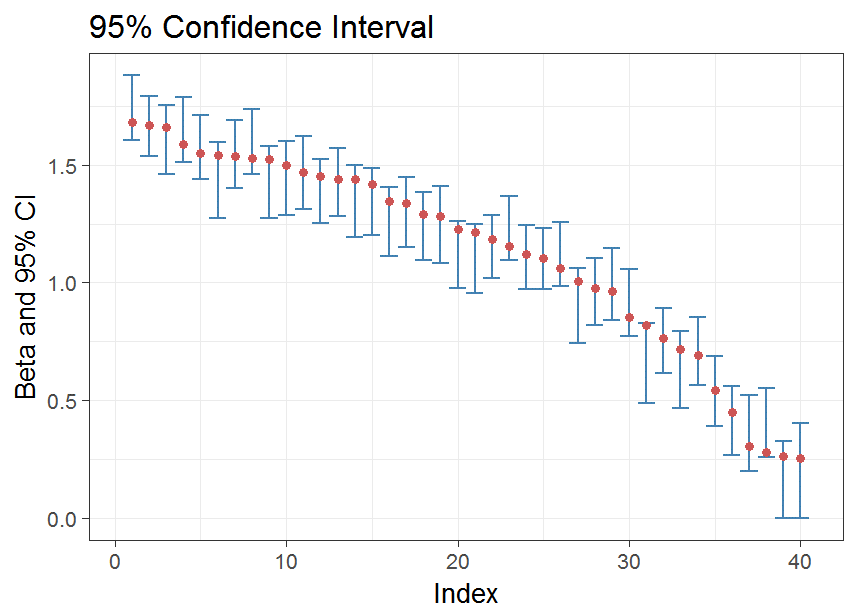
We develop a new framework called Adaptive Bayes for high dimensional inference. In particular, we use deep learning, specifically the variational autoencoders (VAEs), to adaptively learn the prior sparsity information. Based on this prior, we are able to accurately make inference on the regression coefficients. The graph is the Confidence Interval constructed by our approach when the n=500, p = 2000 and number of non-zero coefficients is 40.
Classification of Short Single Lead Electrocardiograms (ECGs) for Atrial Fibrillation Detection using Piecewise Linear Spline and XGBoost
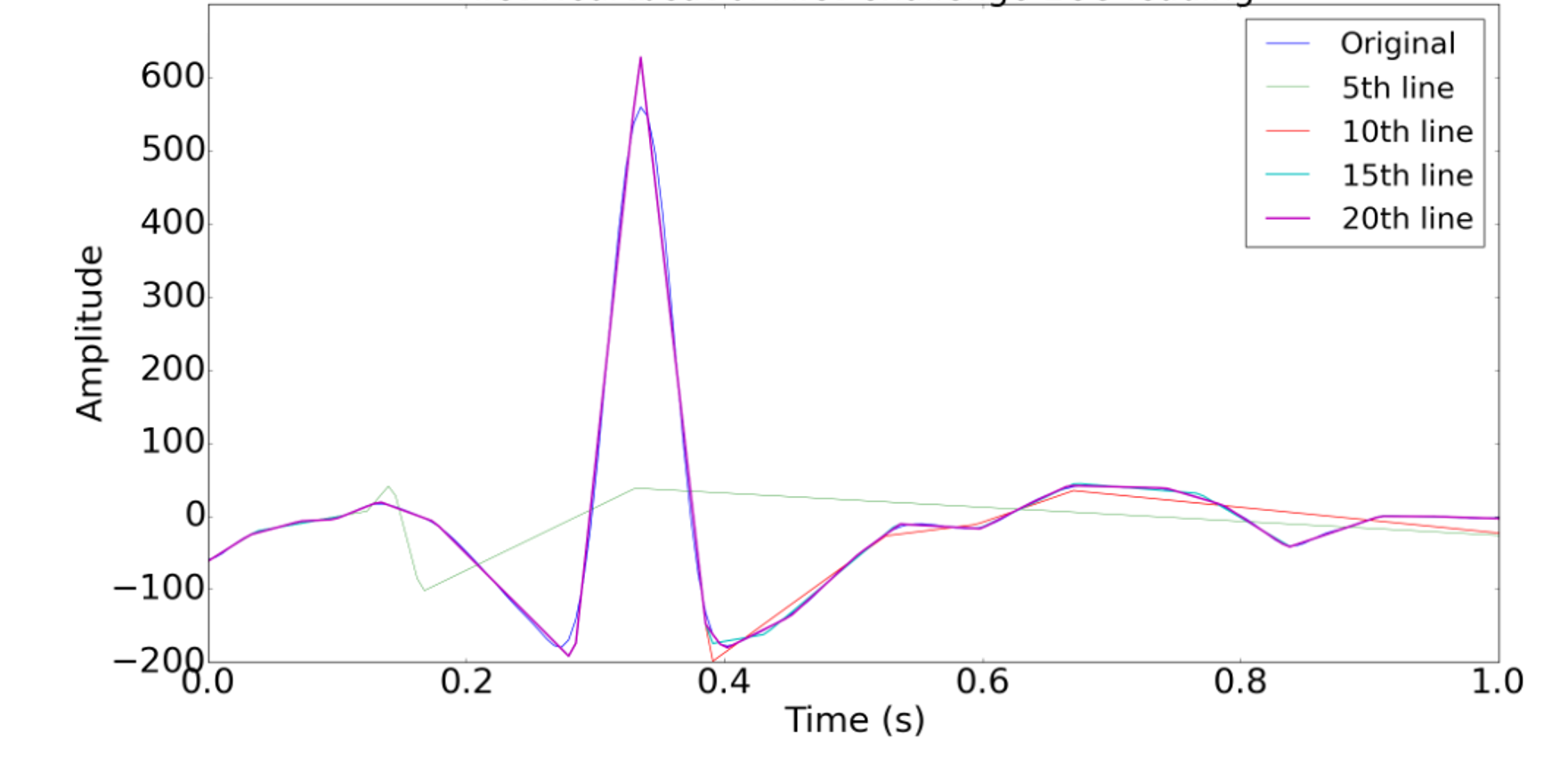
Detection of atrial fibrillation (AF) is important for risk stratification of stroke. We developed a novel methodology to classify the electrocardiograms (ECGs) to normal, atrial fibrillation and other cardiac dysrhythmias as defined by the Physionet Challenge 2017. More specifically, we used piecewise linear splines for the feature selection and a gradient boosting algorithm for the classifier. In the algorithm, the ECG waveform is fitted by a piecewise linear spline, and morphological features related to the piecewise linear spline coefficients are extracted. XGBoost is used to classify the morphological coefficients and heart rate variability features. The performance of the algorithm was evaluated by the PhysioNet Challenge database (3658 ECGs classified by experts). Our algorithm achieved an average F1 score of 81% for a 10-fold cross validation and also achieved 81% for F1 score on the independent testing set. This score is similar to the top 9th score (81%) in the official phase of the Physionet Challenge 2017.
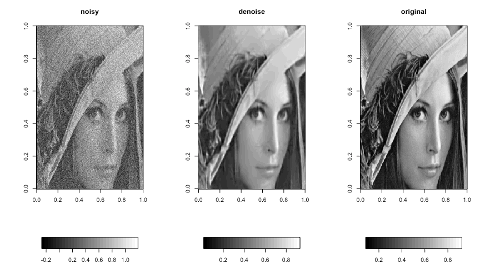
Classification of Short Single Lead Electrocardiograms (ECGs) for Atrial Fibrillation Detection using Piecewise Linear Spline and XGBoost
Detection of atrial fibrillation (AF) is important for risk stratification of stroke. We developed a novel methodology to classify the electrocardiograms (ECGs) to normal, atrial fibrillation and other cardiac dysrhythmias as defined by the Physionet Challenge 2017. More specifically, we used piecewise linear splines for the feature selection and a gradient boosting algorithm for the classifier. In the algorithm, the ECG waveform is fitted by a piecewise linear spline, and morphological features related to the piecewise linear spline coefficients are extracted. XGBoost is used to classify the morphological coefficients and heart rate variability features. The performance of the algorithm was evaluated by the PhysioNet Challenge database (3658 ECGs classified by experts). Our algorithm achieved an average F1 score of 81% for a 10-fold cross validation and also achieved 81% for F1 score on the independent testing set. This score is similar to the top 9th score (81%) in the official phase of the Physionet Challenge 2017.
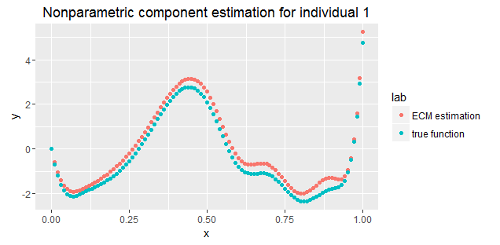
Estimation of Heterogeneity For Multinomial Probit Models
Empirical studies suggest that utility functions are often irregularly shaped, and individuals often deviate widely from each other. In this paper, we introduce a multinomial probit model involving both parametric covariates and nonparametric covariates. To combine heterogeneity across individuals with flexibility, we have two different strategies for the parametric component and the nonparametric component. For the parametric component, heterogeneity is incorporated by the inclusion of random effects. As for the nonparametric component, each individual has a unique individual-level function. However, all those nonparametric components share the same basis. Because the basis is unknown, we use dictionary learning to learn the basis. Additionally, an EM algorithm serves to estimate the multinomial probit models.
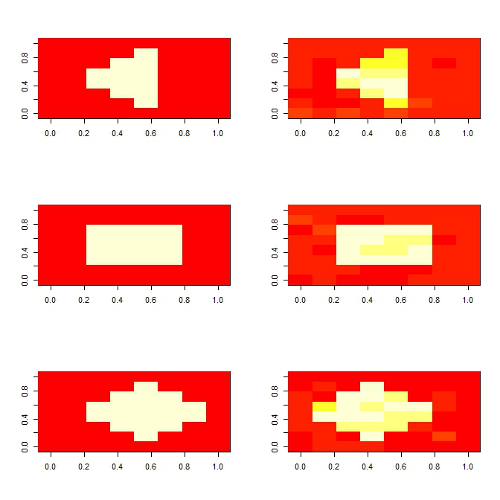
Local Region Image-on-Scalar Regression
In this paper, we propose a new regularization technique to estimate the coefficient image in a image-on-scalar regression model. We have developed a locally sparse estimator when the value of the coefficient image is zero within certain sub-regions. At the same time, the estimator has the ability to explicitly account for the piecewise smooth nature of most images. The ADMM is used to estimate the unknown coefficient images. Simulation and real data analysis have shown a superior performance of our method against many existing approaches. The distributed algorithm is also developed to handle big data. Graphs on the left show an example of the estimators we recovered from the simulation (true on the left, estimator on the right).